






Spark is not tied to the two-stage MapReduce paradigm, and promises performance up to 100 times faster than HadoopMapReduce for certain applications. Spark provides primitives for in-memory cluster computing that allows user programs to load data into a cluster’s memory and query it repeatedly, making it well suited to machine learning algorithms.

Source: intellipaat
![]()
Related Posts
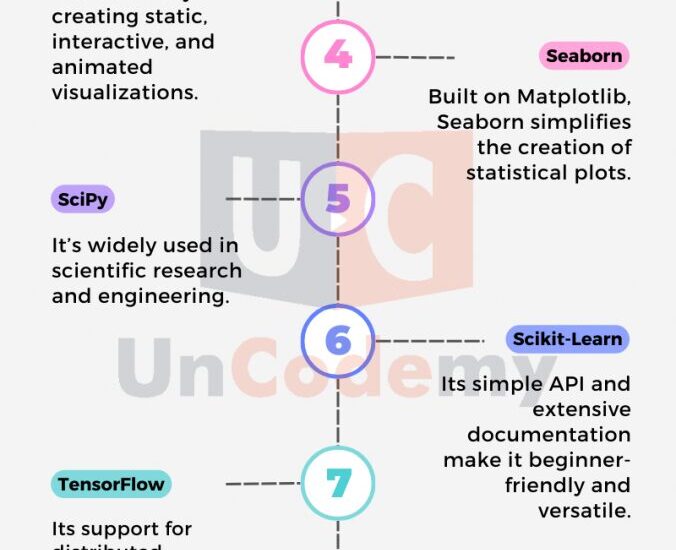
Top 25 Python Libraries for Data Science in 2025
January 23, 2025

Understanding Contentious Probate
November 29, 2024